SnakeYaml反序列化基础
一、基础概念
1.1 SnakeYaml 简介
YAML是”YAML Ain’t a Markup Language”(YAML不是一种标记语言)的递归缩写,是一个可读性高、用来表达数据序列化的格式,类似于XML但比XML更简洁。
在Java中,有一个用于解析YAML格式的库,即SnakeYaml。
SnakeYaml是一个完整的YAML1.1规范Processor,支持UTF-8/UTF-16,支持Java对象的序列化/反序列化,支持所有YAML定义的类型。
1.2 Yaml 语法与结构
YAML基本格式要求:
- YAML大小写敏感;
- 使用缩进代表层级关系;
- 缩进只能使用空格,不能使用TAB,不要求空格个数,只需要相同层级左对齐(一般2个或4个空格)
示例如下:
1 | |
YAML支持三种数据结构:
1、对象
使用冒号代表,格式为key: value。冒号后面要加一个空格:
1 | |
可以使用缩进表示层级关系:
1 | |
2、数组
使用一个短横线加一个空格代表一个数组项:
1 | |
3、常量
YAML中提供了多种常量结构,包括:整数,浮点数,字符串,NULL,日期,布尔,时间。下面使用一个例子来快速了解常量的基本使用:
1 | |
更多的关于YAML的语法及使用可参考:https://www.yiibai.com/yaml
二、SnakeYaml 序列化与反序列化
2.1 SnakeYaml 序列化和反序列化实践
SnakeYaml提供了Yaml.dump()和Yaml.load()两个函数对yaml格式的数据进行序列化和反序列化。
- Yaml.load():入参是一个字符串或者一个文件,经过序列化之后返回一个Java对象;
- Yaml.dump():将一个对象转化为yaml文件形式;
下面使用的环境是用的 SnakeYaml 1.33 版本
- User 类,拥有一个name属性及其setter方法和getter方法
1 | |
- snakeTest.java,序列化新建的User对象为yaml格式内容
1 | |
- 输出结果
1 | |
输出yaml格式的内容,这里”!!”用于强制类型转化,”!!User”是将该对象转为User类,如果没有”!”则就是个key为字符串的Map;
修改 snakeTest.java 程序,反序列化一下输出的 User 对象
1 | |
输出,看到成功反序列化出User对象:
1 | |
2.2 SnakeYaml 反序列化的类方法调用
类比下Fastjson和Jackson的反序列化的类方法调用,这里我们也试下Yaml.load()在调用时会调用将要反序列化的类的哪些方法。
- 修改 User 类
1 | |
- 修改 snakeTest.java
1 | |
输出看到,调用了反序列化的类的构造函数和yaml格式内容中包含的属性的setter方法:
1 | |
2.3 SnakeYaml反序列化过程调试分析
SnakeYaml反序列化的实现主要是通过反射机制来查找对应的Java类,新建一个实例并将对应的属性值赋给该实例。
在前面的反序列化Demo中,在User user = yaml.load(s);上打上断点开始调试。
在load()函数中会先生成一个StreamReader,将yaml数据通过构造函数赋给StreamReader,再调用loadFromReader()函数:
在loadFromReader()函数中,调用了 Baseconstructor.getSingleData()函数,此时type为java.lang.Object,指定从yaml格式数据中获取数据类型是Object类型:
跟进getSingleData()函数中,先创建一个Node对象(其中调用getSingleNote()会根据流来生成一个文件,即将字符串按照yaml语法转为Node对象),然后判断当前Node是否为空且是否Tag为空,若不是则判断yaml格式数据的类型是否为Object类型、是否有根标签,这里都判断不通过,最后返回调用constructDocument()函数的结果:
通过F7继续跟进this.constructDocument跟进具体的反序列化过程,在该函数中可以看到通过this.constructObject()函数调用构造对象后直接返回,可以知道this.constructObject()实现了这个反序列化过程;继续跟进
通过F7跟进this.constructObject();这个函数只有一个简单的判断,然后就继续执行,跟进只有一个hashCode函数,然后就执行了this.constructObjectNoCheck()

通过F7跟进到this.constructObjectNoCheck()中,先判断了recursiveObjects集合里面是否已经包含了相应的节点,没有则继续执行;有则抛出异常;这里是没有,进入else
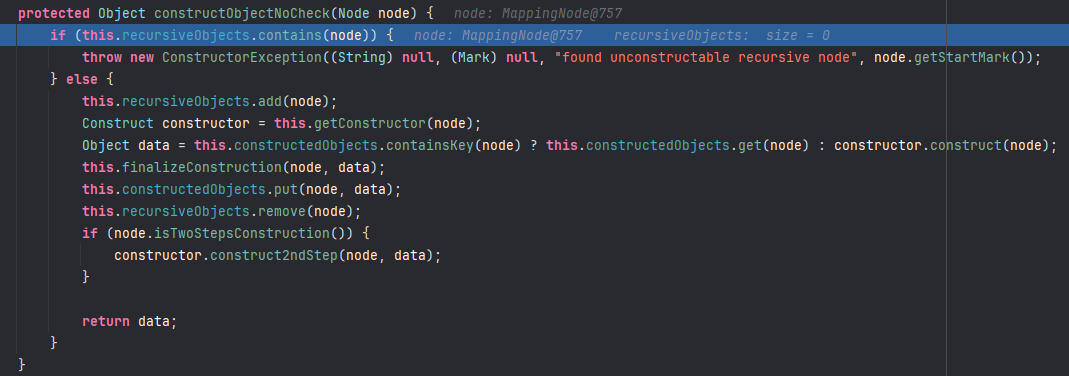
进入else以后,先来将node加入到recursiveObjects集合中,然后再获取node相应的构造函数,这里获取到的是默认的 yaml的构造函数,然后就进入对象构造中;
我们跟进constructor.construct(node)中,来到
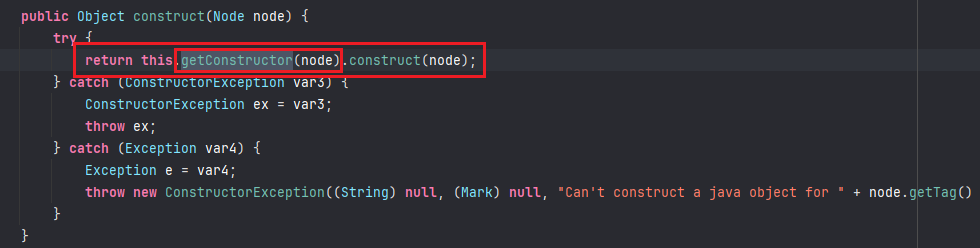
继续跟进getConstructor(node)

然后再跟进getClassForNode,在这个函数中,现根据 tag 取出 className 为目标类,然后调用
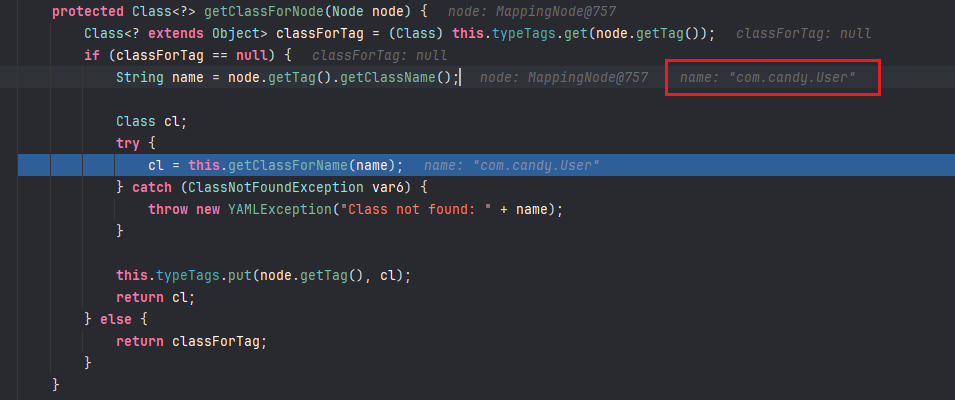
跟进getClassForName,根据获取到的User类名来调用Class.forName()即通过反射的方式来获取目标类User

知道了上述内容之后,我们从下图位置,就是刚才进入 getConstructor(node) 的地方跟进construct(node)函数;
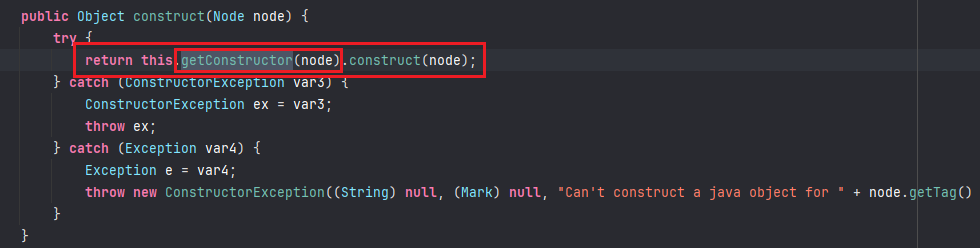
在这个函数中,通过调用newInstance构造了一个 User 对象,目前已经完成了类的实例化,接下来就是进行对象属性的赋值操作;
跟进this.constructJavaBean2ndStep(mnode, obj)
其中会获取yaml格式数据中的属性的键值对,然后调用propert.set()来设置新建的User对象的属性值,跟进上述的 set 方法;

属性值设置完成后,就返回新建的含有属性值的User类对象了。
整个SnakeYaml反序列化的过程就这样。
2.4 总结
SnakeYaml 在反序列化的过程中,首先回提取处序列化的字符串,判断其 tag 是否是 Tag.PREFIX 即”tag:yaml.org,2002:”,是的话进行UTF-8编码并返回该类名;
然后通过反射调用相应类的构造函数进行对象的实例化,然后对对象的属性调用 set 方法进行复制;
以上就是整个反序列化的过程,由于需要实例化对象和对象属性的赋值,因此需要调用构造函数和相应属性的 setter 方法;
参考链接
- https://y4tacker.github.io/2022/02/08/year/2022/2/SnakeYAML%E5%8F%8D%E5%BA%8F%E5%88%97%E5%8C%96%E5%8F%8A%E5%8F%AF%E5%88%A9%E7%94%A8Gadget%E5%88%86%E6%9E%90/#SnakeYaml%E7%AE%80%E4%BB%8B
- https://www.mi1k7ea.com/2019/11/29/Java-SnakeYaml%E5%8F%8D%E5%BA%8F%E5%88%97%E5%8C%96%E6%BC%8F%E6%B4%9E/#SnakeYaml%E7%AE%80%E4%BB%8B